Description
Given a URL startUrl and an interface HtmlParser, implement a Multi-threaded web crawler to crawl all links that are under the same hostname as startUrl.
Return all URLs obtained by your web crawler in any order.
Your crawler should:
- Start from the page:
startUrl - Call
HtmlParser.getUrls(url)to get all URLs from a webpage of a given URL. - Do not crawl the same link twice.
- Explore only the links that are under the
same hostnameasstartUrl.
 As shown in the example URL above, the hostname is
As shown in the example URL above, the hostname is example.org. For simplicity’s sake, you may assume all URLs use HTTP protocol without any port specified. For example, the URLs http://leetcode.com/problems and http://leetcode.com/contest are under the same hostname, while URLs http://example.org/test and http://example.com/abc are not under the same hostname.
The HtmlParser interface is defined as such:
interface HtmlParser {
// Return a list of all urls from a webpage of given url.
// This is a blocking call, that means it will do HTTP request and return when this request is finished.
public List<String> getUrls(String url);
}
Note that getUrls(String url) simulates performing an HTTP request. You can treat it as a blocking function call that waits for an HTTP request to finish. It is guaranteed that getUrls(String url) will return the URLs within 15ms. Single-threaded solutions will exceed the time limit so, can your multi-threaded web crawler do better?
Idea
Below are two examples explaining the functionality of the problem. For custom testing purposes, you’ll have three variables urls, edges and startUrl. Notice that you will only have access to startUrl in your code, while urls and edges are not directly accessible to you in code.
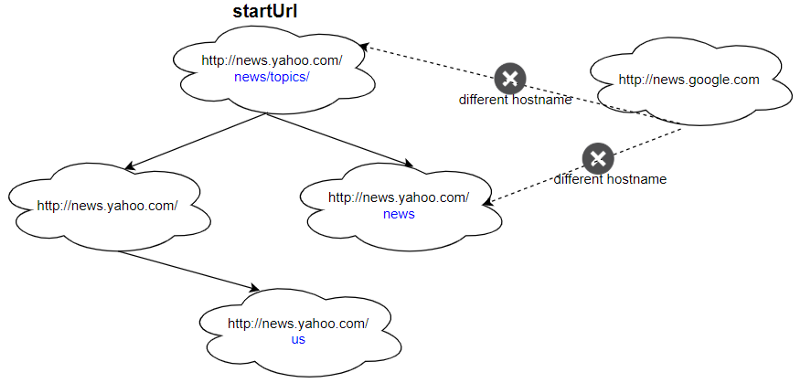
Input:
urls = [
"http://news.yahoo.com",
"http://news.yahoo.com/news",
"http://news.yahoo.com/news/topics/",
"http://news.google.com",
"http://news.yahoo.com/us"
]
edges = [[2,0],[2,1],[3,2],[3,1],[0,4]]
startUrl = "http://news.yahoo.com/news/topics/"
Output: [
"http://news.yahoo.com",
"http://news.yahoo.com/news",
"http://news.yahoo.com/news/topics/",
"http://news.yahoo.com/us"
]
Be multi threading(or multi processing), Python recommend use ThreadPoolExecutor (or ProcessPoolExecutor)to protect the threads (or processes) in a safe state when it executing. And this question maybe execute under a virtual environment on leetcode platform, so I guess take the ThreadPoolExecutor is a better choice.
So, I write 2 methods of the class Solution , one for extract hostname from url name get_hostname(), another one for filter url which is not visited name visit_url().
Then, using the ThreadPoolExecutor to submit task visit_url for each url which is in the queue, and call future.result() to execute each visit_url with url.
Finally, shutdown the ThreadPoolExecutor to release resources and return a list for visit url result.
Solution
# """
# This is HtmlParser's API interface.
# You should not implement it, or speculate about its implementation
# """
#class HtmlParser(object):
# def getUrls(self, url):
# """
# :type url: str
# :rtype List[str]
# """
from concurrent.futures import ThreadPoolExecutor
from threading import Condition
class Solution:
def __init__(self) -> None:
self._queue = list()
self._lock = Condition()
self._visited = set()
def get_hostname(self, url: str):
hostname = '.'.join(url.split('/')[2].split('.')[1:])
return hostname
def visit_url(self, url: str):
next_urls: List[str] = self._parser.getUrls(url)
with self._lock:
for next_url in next_urls:
if next_url not in self._visited and self.current_hostname == self.get_hostname(next_url) :
self._visited.add(next_url)
self._queue.insert(0,next_url)
def crawl(self, startUrl: str, htmlParser: 'HtmlParser') -> List[str]:
self._queue.insert(0,startUrl)
self._visited.add(startUrl)
self.current_hostname = self.get_hostname(startUrl)
self._parser = htmlParser
executor = ThreadPoolExecutor()
while self._queue:
urls = [self._queue.pop(), ]
while self._queue:
urls.append(self._queue.pop())
excecutor_list = [executor.submit(self.visit_url, (url)) for url in urls]
for future in excecutor_list:
future.result()
executor.shutdown()
return list(self._visited)