最近利用 GA4 、 UA ,以及團隊的開發產品所蒐集到的資料,協助團隊進一步了解產品的成效與成本的利用情況。團隊的開發與產品環境皆建立在 Google Cloud Platform (GCP) 上,在分析 GCP billing report 的原始資料時,也引發了我 “對於同仁們對於如何利用開發環境” 感到好奇,寫下這篇文章作為紀錄。
在產品的開發中,團隊消耗成本最高的前幾項排名既在意料之中,Google Compute Engine (GCE)、 Cloud Functions 、 BigQuery 以及 Google Cloud Storage,但細項的部分也在意料之外。
Google Compute Engine (GCE)
在 GCP 上,無論我們開啟的是一般的 VM 機器,又或者是 Google Kubernetes Engine (GKE) 的 Node , 本身所使用的資源單位都可以稱為 Instance ; 換句話說,可以簡單的將 Instance 理解為能夠提供絕大部分 VM 相關功能的資源,如 : vCPU、Memory、Disk、Netwroking 以及機器學習最需要的 GPU (TPU)等等,因此這一部份的資源用量也都會被歸因到 GCE 上。
將 billing report data 依據 SKU 進行加總並命名為 「Cost」欄位,再對 「Cost」欄位做 kernel density estimation (kde) 後可以得到 「Cost」的群聚密度,同時也能獲取一組較為合理的上下邊界以利取得離群值,「Cost」的離群值對於 billing report 的意義則在於找出異常的費用;以 下將固定使用 kde 取離群值的作法,因此不再一一贅述。
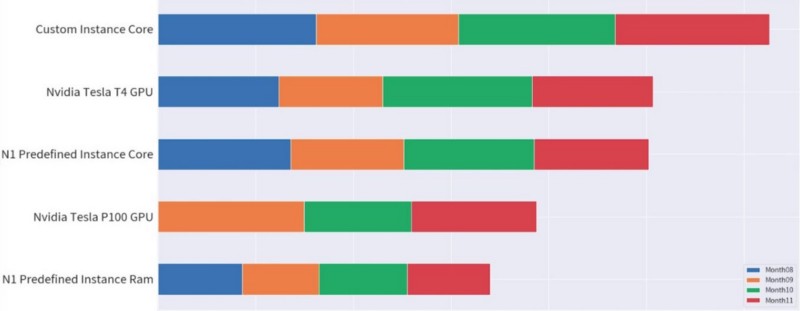 從離群值得知,Instance Core 、 Instance Ram 以及 GPU 的費用都是比較可觀的
從離群值得知,Instance Core 、 Instance Ram 以及 GPU 的費用都是比較可觀的
Instance:
依據 Figure 1. GCE charged detail 給出的資訊,Instance 分為 Custom 與 N1-Predefined 兩種類別,這兩種類別在團隊中分別作為 GKE Node 與 GCE instance 來使用。依據 Google 在 GCE 定價的文件中可以得知, 1. Instance 的 CPU 與 Memory 是分別以 “running time” 進行收費, 2. custom machine type 會比 predefined machine type 收取更多費用。
觀察 Custom Instance Core 、 N1 Predefined Instance Core 以及 N1 Predefined Instance Ram 的堆疊圖也可以發現,三者在 8 月至 11 月的費用並沒有出現 burst peak , 反而在變化上呈現相對平滑的狀況;對於開發團隊來說,這其實不是一個正常的表現: 有限的人力伴隨著開發迭代週期,會出現大量使用 CPU 計算以驗證 feature 的開發情況,也會進行伴隨著壓力測試出現大量載入資料迫使 Memory 使用量增加的情況。
因此,最可能的情況其實是: 團隊使用了超過需求量的資源。因為供過於求,導致收費並沒有發生變化,尤其是 GKE Node 應該要有卻沒有呈現的 auto-scaling 效益,最終的結論便是資源溢出造成的浪費,我們也在發現後的第一時間即時做出調整與改善。
GPU:
團隊所開發的產品 ADsvantage | AI 智慧寫手 是一款 AI 智能廣告工具,24 小時智能監控,讓你不必隨時在線,AI 幫你顧廣告, 因此需要 GPU 來訓練 model 以及應用也是很合理的事情 (防不勝防,自己的業配自己寫XD)
Cloud Functions
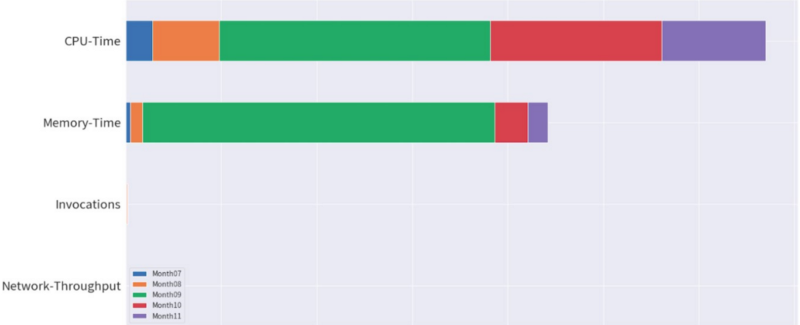 和 GCE Instance 收費相同, Cloud Functions 也是以 CPU 和 Memory 的 “running time” 分別進行收費;差別在於 GCE 收費是以 Hour 作單位,而 Cloud Functions 則是以 100 毫秒(ms) 作為計費單位;即使 Cloud Function 調用 (Invocations) 次數達到千萬次,對於調用的收費也遠遠小於 CPU 和 Memory。
和 GCE Instance 收費相同, Cloud Functions 也是以 CPU 和 Memory 的 “running time” 分別進行收費;差別在於 GCE 收費是以 Hour 作單位,而 Cloud Functions 則是以 100 毫秒(ms) 作為計費單位;即使 Cloud Function 調用 (Invocations) 次數達到千萬次,對於調用的收費也遠遠小於 CPU 和 Memory。
這邊也多提一句,千萬不要把 Cloud Functions 當作 API 來使用, Cloud Functions 有它適合的場景,但顯然不是"永保在線"的服務。
BigQuery
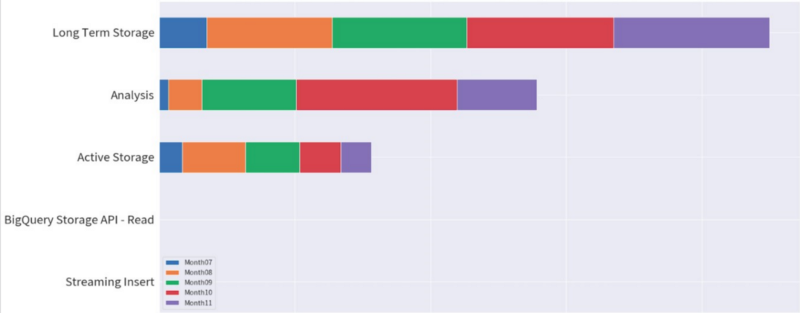 Long-Term Storage 與 Active Storage 的識別條件: 超過90天沒有 modify / 90 天內仍有 modify 的資料表; Analysis 則是相對直覺的 Query 費用。
Long-Term Storage 與 Active Storage 的識別條件: 超過90天沒有 modify / 90 天內仍有 modify 的資料表; Analysis 則是相對直覺的 Query 費用。
Figure 3. BigQuery charged detail 告訴我們,目前開發環境中的 BigQuery 有太多 Long-Term 的資料被儲存著,這部分有屬於 machine learning 的 train data set ,當然也有太久沒有使用過的資料;同時資料的多寡也影響了 Analysis 每次的收費,因此我們對資料集進行了一次評估與審核,剔除掉已不再需要的資料,以期節省費用。
Google Cloud Storage (GCS)
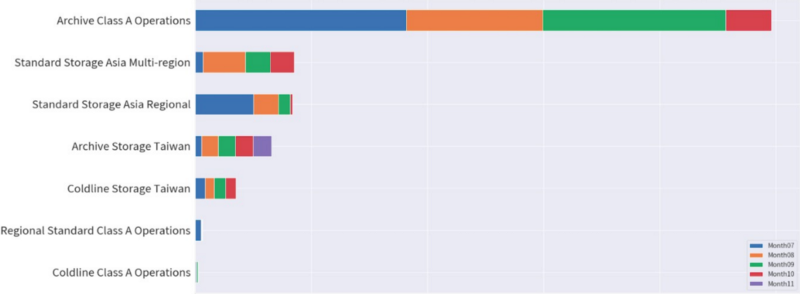 GCS 提供了可對 儲存桶(bucket) 內的檔案 (objects) 實施 生命週期(life-cycle)管理的功能: 透過規則的設定,可以將符合規則天數的 objects 從 standard (nearline / coldline) 等級變更為 nearline、coldline 以及 archive 等級,各等級有不同的收費標準。如: archive 儲存的費用相對最低,但 access 的費用最高, standard 的儲存收費相對最高,但不收取 access 的費用 (如果有產生 traffic 則有可能會進行 bandwidth 的收費)。
GCS 提供了可對 儲存桶(bucket) 內的檔案 (objects) 實施 生命週期(life-cycle)管理的功能: 透過規則的設定,可以將符合規則天數的 objects 從 standard (nearline / coldline) 等級變更為 nearline、coldline 以及 archive 等級,各等級有不同的收費標準。如: archive 儲存的費用相對最低,但 access 的費用最高, standard 的儲存收費相對最高,但不收取 access 的費用 (如果有產生 traffic 則有可能會進行 bandwidth 的收費)。
在過往的經歷中,即使資料已經沒有被使用到了仍然會"習慣性"的將其進行封存,以待某天會再度使用。然而多的是,我不知道的 archive 一直在被 access 的事…
想當然是馬上對 objects 進行盤點,並加入到資料審核與剃除的流程中啦!!
Summary
經過這次的分析,也確實找出很多以往在開發中總不經意忽略的小事,然而正是這些最重要的小事,在收費上卻往往變成了大事。
與一起踩過雷的同行共勉之,也希望這次的分析能夠對於日後使用雲端平台資源更加警慎。