在 [GCP Billing Analytics] 中提到過關於 Cloud Functions 的計費超乎預期,進一步分析開發的使用習慣後,也找出部分功能應該將其從 Cloud Functions 搬遷至基於 GCE instances 的服務上,以達到節費的期望。
在原先的設計中,我們將 Cloud Functions 作為 ETL data flow 的其中一個環節,透過 Pub/Sub trigger Cloud Functions 的方式使其運作;考慮到 Pub/Sub subscriber push/pull 的 Ack 等待時間有著最長 600 秒的限制,我將這部分需要搬遷的 Cloud Functions 大致分為兩種需求
靜態資料源: 在提取資料時,可預期資料是存在且可被存取的動態資料源: 可能發生資料不存在,或者是無法存取的情況
本篇文章是記錄
- 用
Airflow DAG(Directed Acyclic Graph) 替代Cloud Function環節以處理靜態資料源的方法 Airflow GCP Operators使用- 在
DAG 中平行處理(parallel processing)的方式
動態資料源的處理方案 > Migrate Google Cloud Functions to Kubernetes
Design Change
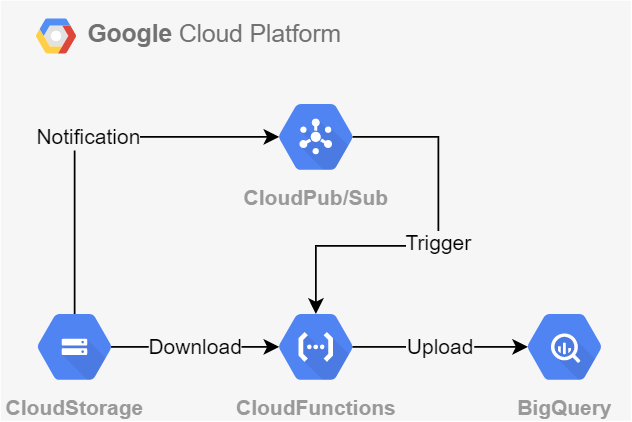 Figure 1 是一個經典的使用案例,透過 GCS notification 的機制,當 bucket 中有檔案 (Object) 異動時,將異動的資訊 publish 到指定的 Pub/Sub Topic。 部署 Cloud Function 可以指定
Figure 1 是一個經典的使用案例,透過 GCS notification 的機制,當 bucket 中有檔案 (Object) 異動時,將異動的資訊 publish 到指定的 Pub/Sub Topic。 部署 Cloud Function 可以指定--trigger-topic 接受 Topic 的觸發,使得 Cloud Function 可以接收異動檔案的資訊,如: bucket name、object path , 進行轉置 (Transform) 處理後將結果存放到 Big Query 。
這也是我稱呼為靜態資料源的原因
由於訊息傳遞的時間相對迅速,當 Cloud Function 需要擷取對應的檔案時,該檔案存在於 GCS 上的對應位置
Airflow DAG & Operators
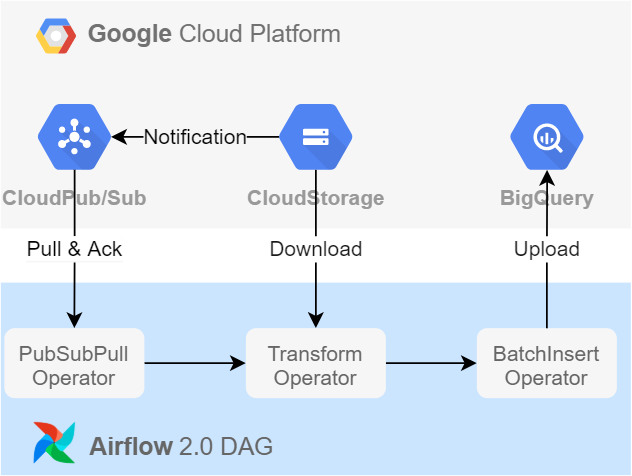 Figure 2 則用 Airflow 2.0 DAG 替代 Cloud Function , Airflow 是 Python based 的工作流管理系統,可以幫助開發者將工作流程標準化以及執行重複性的工作,我認為滿適合應用於靜態資料源的場景上。
Figure 2 則用 Airflow 2.0 DAG 替代 Cloud Function , Airflow 是 Python based 的工作流管理系統,可以幫助開發者將工作流程標準化以及執行重複性的工作,我認為滿適合應用於靜態資料源的場景上。
並且 Airflow 官方也提供對應 GCP 服務 Operators 的文件 與 安裝方式。可以直接使用,也可以參考 Operators 的 Source Code 來重新編寫自定義的 Operator;如 Figure 2 的 PubSubPullOperator 便能直接使用官方提供的 packages ,而 TransformOperator與 BatchInsertOperator 也可以尋找到對應 operator source code 以進行參考與改寫,以後有機會的話在另外撰寫文章記錄。
Parallel Processing in DAG
在 Figure 2 中改為使用 pull message 的方式,因此可以透過 PubSubPullOperator 來設置每次拉取訊息數量的上限;
然而,考慮到 Airflow schedule 的最小間隔單位為 1 分鐘,一旦 publish message 的數量與日遽增、或是出現 burst 的情形時,僅憑一組 PubSubPullOperator > TransformOperator > BatchInsertOperator 的工作流程設置可能無法消化;因此就需要考量在 DAG 中建立多組的工作流程,以進行平行處理。
 Figure 3 是我理解 Pub/Sub 拉取訊息的工作原理(若有錯誤也煩請指正,感謝),訊息的傳遞步驟略可簡述為:
Figure 3 是我理解 Pub/Sub 拉取訊息的工作原理(若有錯誤也煩請指正,感謝),訊息的傳遞步驟略可簡述為:
Step 1. Publish message to Topic
Step 2. Message push into subscriber group queue by fanout mode
Step 3. Single/Multi puller to pull message from a subscriber group queue
這樣一想就比較簡單了,只要在 DAG 中建立多組的 PubSubPullOperator > TransformOperator > BatchInsertOperator 工作流程,每個 PubSubPullOperator 都扮演著 Puller 的角色。
如 Figure 4 展示的工作流程設置,這樣就能達成平行處理的構想啦! 同時,我也採用了 DummyOperator 作為整個 DAG 的起始與完成,主要是希望在使用 Airflow UI 時能夠比較好的表達 DAG 的工作狀態。
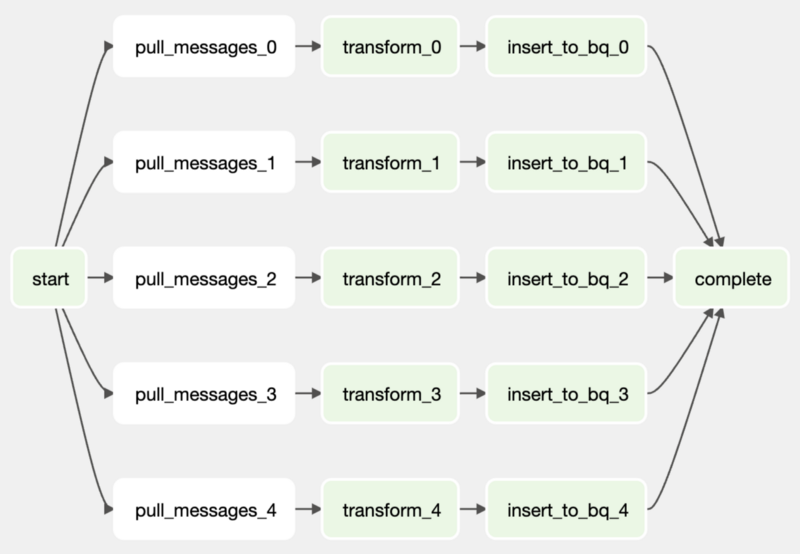
Python example code for parallel processing in DAG
PARALLEL: int = 5
start = DummyOperator(task_id='start')
complete = DummyOperator(task_id='complete')
for i in range(PARALLEL):
pull_message = PubSubPullOperator(task_id=f'pull_message_{i}')
transform = TramsformOperator(task_id=f'transform_{i}')
insert_to_bq = BatchInsertOperator(task_id=f'insert_to_bq_{i}')
start >> pull_message >> transform >> insert_to_bq >> complete
另外,在能估算出單位時間 publish 的 message 數量,便能簡單地將 schedule 間隔時間、單次拉取訊息的數量上限,以及工作流程組數視為調整參數,以調整工作流程的處理效率。